
Как получить визу талантов в Великобритании
Все, что нужно знать о визе талантов, ее преимуществах и сроках подачи заявки.
8 минут


На IT-конференции beetech conf, прошедшей 22 апреля, один из создателей казахской языковой модели BeeBERT Бексултан Сагындык рассказал о возможностях ее использования и перспективах развития ИИ в Казахстане.
Kaz-RoBERTA-conversational (BeeBERT) — это языковая модель, обученная на большом массиве данных на казахском языке. Модель можно применить к текстовой информации, внедрять в чат-боты и системы анализа контента.
В компании Beeline Казахстан BeeBERT уже улучшила качество распознавания запросов от клиентов в чат-боте на 18%. Модель лучше определяет язык интерфейса на основании запроса клиента. Например, если один запрос от клиента был на русском, а другой — на казахском, благодаря BeeBERT язык интерфейса чат-бота будет меняться. После доработки модель сможет переводить, резюмировать и упрощать, а также понимать тональность текстов на казахском языке.
Разработкой языковой модели BeeBERT занималась одна из команд отдела Big data компании Beeline: Бексултан Сагындык, Санжар Мурзахметов, Темирлан Жоламан и Даулет Махметов. Разработчики собирали, обрабатывали данные и обучали языковую модель около трёх месяцев. А шестого апреля команда опубликовала модель BeeBERT на платформе Hugging Face. Это одна из самых популярных площадок для публикации открытых наработок в области Deep Learning. На ней есть разработки таких компаний как Google и Microsoft.
Команда разработчиков языковой модели BeeBERT: Санжар Мурзахметов, Бексултан Сагындык, Темирлан Жоламан и Даулет Махметов
С момента публикации BeeBERT с начала апреля её скачали более 100 раз. Подобная публикация модели в открытый доступ — первый случай среди крупных технологических компаний Казахстана.
«IT-комьюнити в Казахстане небольшое, и разработки, в основном, направлены на нужды компаний. А в самих компаниях нет высокого уровня открытости или желания, которые позволили бы делиться результатами работы с большой аудиторией. Надеемся, что этот шаг послужит хорошим примером для других», — рассказывают создатели.
На платформе Hugging Face любой пользователь может протестировать модель BeeBERT в разделе Hosted inference API. В пустой строке нужно ввести предложение на казахском и «спрятать» одно из слов, используя <mask>. Далее модель покажет слова, которые с большей вероятностью могут стоять вместо <mask>. А для интеграции в свои чат-боты пользователю потребуется небольшой опыт работы с языком программирования Python.
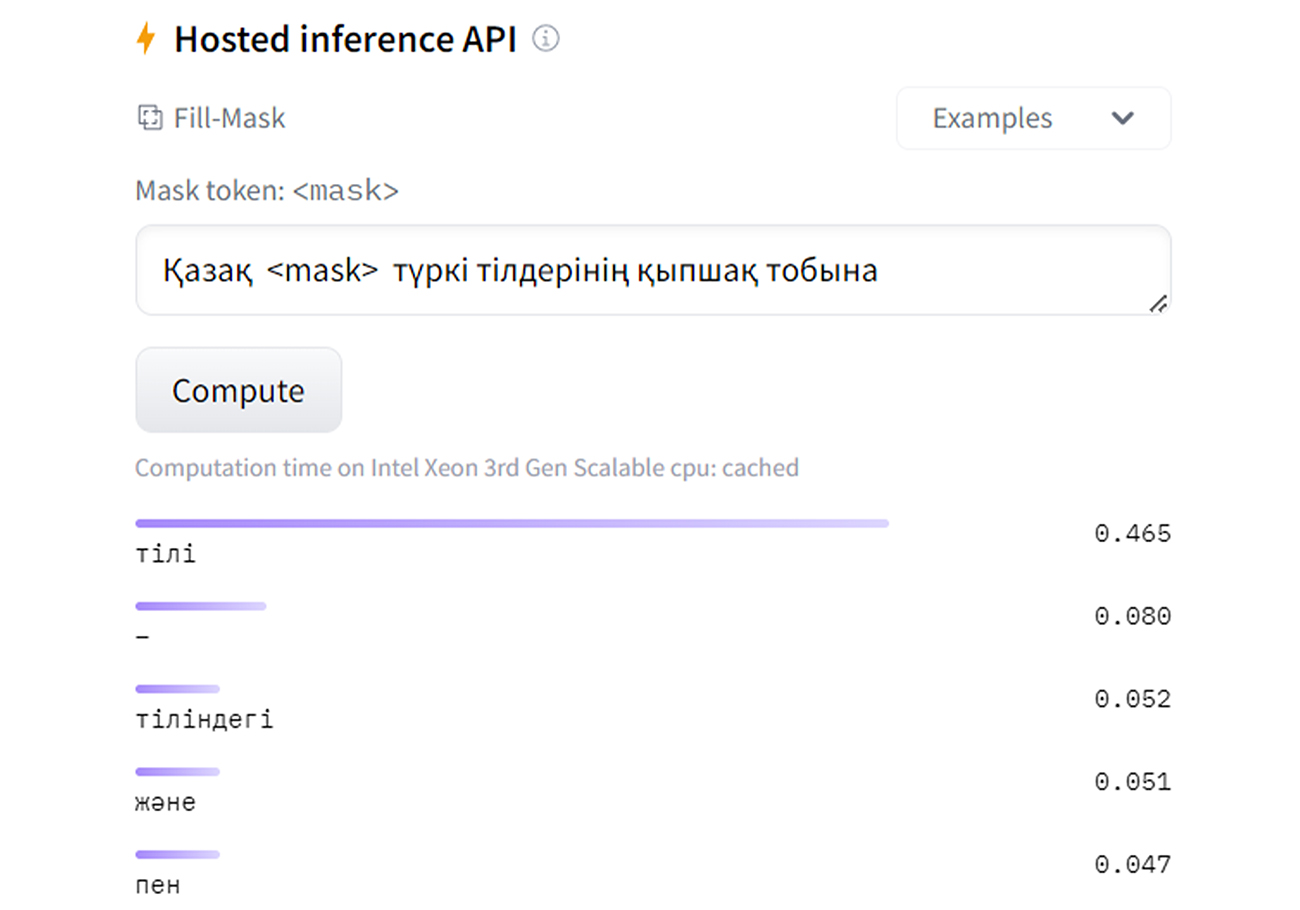
Пример максировки слова на казахском языке в языковой модели BeeBERT
Языковая модель BeeBERT может быть использована в приложениях, связанных с текстом, то есть практически во всех. Модель может определять казахский язык в тексте, извлекать имена, названия городов и другие данные, понимать тональность и эмоции, исправлять орфографические ошибки, искать ключевые слова. Эти функции языковой модели можно использовать, если вы, например, занимаетесь созданием чат-бота небольшого банка. BeeBERT поможет увеличить количество тем, по которым ваши клиенты смогут получить ответ на казахском языке.
«Архитектура нашей модели не позволяет использовать ее для генерации текста, поэтому она не способна вести диалог с пользователем, но модель можно использовать как часть диалоговой системы», — отмечает Бексултан.
По словам разработчика, одна из сложностей в создании языковой модели BeeBERT была в недостатке текстов на казахском языке в открытом доступе по сравнению с русским или английским. Говоря о трудностях, Бексултан добавляет:
«Также сложность заключается в оценке результатов разработки на казахском языке: для понимания уровня качества моделей на русском языке есть бенчмарки Russian GLUE. Это набор датасетов с разметкой по различным задачам, которые позволяют понять, насколько хорошо модель понимает язык. Для разработки таких бенчмарков для казахского языка нужно привлекать исследователей и лингвистов».
Команда разработчиков планирует улучшать модель BeeBERT и также опубликовать следующие версии в открытый доступ.
Также Бексултан и Санжар опубликовали на платформе Hugging Face большой мультидоменный текстовый датасет для казахского языка размером 25 гигабайт. Он представляет из себя 25 миллионов текстов, в которых находится два миллиарда слов/токенов, которые были собраны из различных открытых источников — новостей, книг, википедии. Этот датасет разработчики других компаний могут использовать для обучения своих небольших языковых моделей или для исследовательских задач.
.jpg)
.jpg)
.jpg)
.jpg)
Конференция beetech
Получай актуальные подборки новостей, узнавай о самом интересном в Steppe (без спама, обещаем 😉)
(без спама, обещаем 😉)


